Date de publication : 30 juin 2009
Cet article présente l'une des nouvelles fonctionnalités de C++0x (prochain standard du langage C++) : la sémantique de déplacement (également appelée sémantique de mouvement, ou encore move semantics en version originale). Vous apprendrez ici les motivations de l'inclusion de cette nouveauté, ainsi que les bases de son utilisation.
Depuis sa première standardisation en 1998, le langage C++ n'a connu aucune évolution majeure. Ces plus de dix années d'existence ont révélé quelques manques. Heureusement, le nouveau standard du langage (nom de code C++0x) arrive à grands pas et ses nouvelles fonctionnalités vont permettre de combler ces manques.
La sémantique de déplacement, sujet du présent article, est l'une de ces nouvelles fonctionnalités.
![[Note]](/common/images/note.gif) | |
Dans la suite de cet article, de même que nous utilisons le nom de code C++0x pour désigner le futur standard, nous ferons parfois référence au langage C++ des standards de 1998 et de 2003 (mise à jour mineure du standard de 1998) par l'appellation C++98. |
| |
Par soucis de lisibilité, toutes les fonctions membres des codes sources qui vont suivre ont été déclarées inline. Notez bien qu'il s'agit d'un choix purement visuel et qu'en pratique il n'est pas toujours légitime d'écrire votre code ainsi ! |
Avant d'aborder cette nouvelle fonctionnalité, commençons par mettre en évidence quelques unes des limites du premier standard.
Lors du transfert d'un objet (récupération de la valeur de retour d'une fonction, initialisation d'un objet membre, etc.), de nombreuses copies sont créées inutilement. Dans le cas d'objets de taille conséquente, la multiplication des copies peut entrainer une sévère dégradation des performances. Les deux exemples suivants présentent chacun un cas de figure récurrent où une ou plusieurs copies sont illégitimement créés.
Le programme ci-dessous définit une classe bottle (bouteille) ayant pour membre un objet de la classe message. Un objet de type bottle est créé dans la fonction main(). Cet objet bottle est initialisé avec une instance anonyme de message.
#include <iostream>#include <string>classmessage{public:message(conststd::string&text):text_(text){std::cout<<"Construction\n";}message(constmessage&m):text_(m.text_){std::cout<<"Copy construction\n";}~message(){std::cout<<"Destruction\n";}private:std::string text_;};classbottle{public:bottle(constmessage&m):m_(m){}private:message m_;};intmain(){//initialisation d'un objet bottle avec une instance anonyme de messagestd::cout<<"[Creation of a bottle]\n"; bottle b(message("Help!")); std::cout<<"[Bottle created]\n";return0;}
Alors qu'il n'existe qu'une seule instance non-temporaire de message (la variable membre de la classe bottle), une copie va être créée :
[Creation of a bottle] Construction Copy construction Destruction [Bottle created] Destruction
Il est pourtant inutile de produire une copie de l'instance de message de la fonction main(), étant donné que cette instance est anonyme et temporaire ; elle ne pourra pas être utilisée ou modifiée dans la suite du code. Elle sera par ailleurs détruite une fois la construction de l'objet bottle achevée.
À quoi bon copier un objet A vers un objet B si l'objet A doit être immédiatement détruit ? Voilà une incohérence à laquelle le standard de 1998 ne peut échapper.
Réutilisons la classe message dans un autre contexte. Soit une fonction create_message(), créant et renvoyant un objet de type message :
messagecreate_message(conststd::string&addressee){std::string text; text ="Dear "+ addressee +",\n"; text +="I grounded on a desert island and am currently starving.\n"; text +="I would be grateful if you could take me out of this "; text +="somewhat delicate situation.\n\n"; text +="Sincerely yours,\n"; text +="Clancy Plusplus";returnmessage(text);}intmain(){std::cout<<"[Creation of a message]\n"; message help_message =create_message("Captain of the ship over there"); std::cout<<"[Message created]\n";return0;}
Ce programme produit la sortie suivante (à laquelle a été ajoutée une numérotation) :
[Creation of a message] Construction (1) Copy construction (2) Destruction (3) Copy construction (4) Destruction (5) [Message created] Destruction (6)
Que nous indique cette sortie ?
create_message(), appelée depuis main(), crée une instance de message.create_message("Captain of the ship over there") située dans la fonction main().create_message() se termine. Les objets alloués sur la pile par cette fonction, comprenant l'instance de message, sont détruits un à un.main(), c'est l'objet temporaire anonyme qui est copié dans l'objet help_message...help_message est détruit. Il n'existe alors plus d'instance de message.
Cette fois ci, ce ne sont non pas une, mais deux copies qui sont créées. Là encore, leur création est illégitime, car toutes les instances anonymes sont détruites immédiatement après avoir été copiées.
| La RVO |
|---|---|
Dans ce cas particulier, il se trouve que la plupart des compilateurs actuels appliquent une optimisation visant à éliminer la création de ces copies dans le binaire final. Cette optimisation est connue sous le nom de RVO (Return Value Optimization, Optimisation de la valeur de retour). Toutefois, cette RVO ne peut pas toujours s'appliquer et le standard n'oblige en rien les compilateurs à l'implémenter. |
Il est parfois utile en C++ de déclarer une classe comme étant non-copiable.
Par exemple, le code ci-dessous déclare une classe boat (bateau). Cette classe contient un vecteur de marines (marins) représentant l'équipage du bateau. Étant donné qu'un marin ne peut être à bord que d'un seul bateau et que copier un marin n'a aucun sens, nous décidons de rendre les objets des classes boat et marine non-copiables :
classboat;classmarine{public:marine(conststd::string&name):name_(name){}//rejoindre l'équipage d'un bateauvoidjoin(boat*b){boat_ = b;}private://on désactive la construction par copie...marine(constmarine&);//...et l'assignation par copieconstmarine&operator=(constmarine&); std::string name_; boat*boat_;};classboat{public:boat(conststd::string&name):name_(name){}voidadd(marine*m){m->join(this); crew_.push_back(m);}private://on désactive la construction par copie...boat(constboat&);//...et l'assignation par copieconstboat&operator=(constboat&); std::string name_; std::vector<marine*>crew_;};
À présent, imaginons que nous souhaitons écrire une fonction fabrique prenant en argument un nom et un capitaine pour le bateau et renvoyant une instance de boat. Nous écrivons naïvement cette première version :
boatcreate_boat(conststd::string&boat_name, marine*captain){boatnew_boat(boat_name); new_boat.add(captain);returnnew_boat;}
Hélas, et il fallait s'y attendre, ce code est erroné. Il n'est pas possible de renvoyer un objet boat, car en C++98, renvoyer signifie copier. Or, nous avons justement interdit explicitement la copie d'un objet de cette classe.
Dans ce cas de figure, la seule solution pour contourner le problème consiste à allouer un objet sur le tas et à renvoyer un pointeur vers lui :
boat*create_boat(conststd::string&boat_name, marine*captain){boat*new_boat =newboat(boat_name); new_boat->add(captain);returnnew_boat;}
Nous sommes donc forcés de produire une allocation sur le tas qui, comme vous le savez certainement, est plus couteuse en ressources qu'une allocation sur la pile. De plus, la responsabilité de la destruction de l'objet n'étant pas attribuable, l'usage d'un pointeur intelligent serait ici préférable. Cet usage provoquera lui aussi une consommation de ressources accrue.
Le problème est que cette allocation sur le tas n'est justifiée que par la contrainte de copie induite par le langage. S'il existait un moyen de renvoyer l'objet boat sans avoir à le copier, cette allocation n'aurait plus lieu d'être.
Le point commun entre toutes les situations évoquées dans la section précédente est une utilisation systématique et inadaptée de la copie au sein du mécanisme interne du langage. Il existe pourtant une alternative à la copie pour créer un objet à partir d'un autre. Cette alternative est le déplacement.
Afin de mieux introduire le concept du déplacement, nous allons dans un premier temps détailler ce que nous savons de la copie à travers l'étude d'un exemple concret. Ce même exemple servira de soutien à la présentation de cette nouvelle technique qu'est le déplacement.
L'exemple en question est le modèle d'une barque (classe craft), une classe simple composée d'un objet body (la coque de la barque) et de deux objets oar (rame). Par soucis de simplicité, ces deux derniers types ne définissent aucun champ. De même, nous considérons que leurs constructeurs ne peuvent lancer d'exception.
Voici un diagramme d'objets UML représentant une instance de la classe craft :
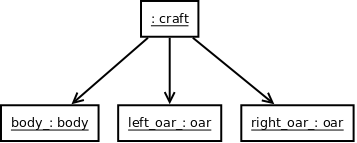
Nous étudierons donc la copie d'un objet craft, puis son déplacement.
Que se passe-t-il lorsque nous copions un objet ? Vous le savez certainement : tous les champs composant cet objet (l'objet source) sont tour à tour copiés (ceci de façon récursive jusqu'à la copie des champs de types primitifs) pour former un nouvel objet du même type (l'objet destination). Par exemple, la copie de notre objet craft pourrait s'illustrer comme ceci :
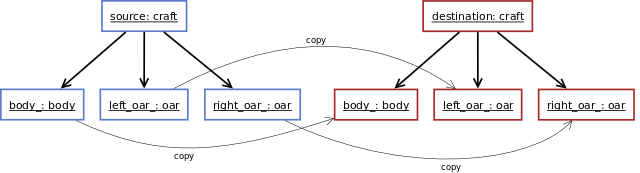
C'est précisément ce que l'on indique lorsque l'on écrit nous-même le constructeur par copie :
classcraft{public:craft(){}//constructeur par copiecraft(constcraft&o):body_(o.body_),left_oar_(o.left_oar_),right_oar_(o.right_oar_){}private:body body_; oar left_oar_; oar right_oar_;};
Le déplacement consiste à déposséder l'objet source des ses champs afin de les attribuer à un objet destination nouvellement créé.
Lorsque l'on effectue le déplacement d'un objet craft, tous les objets composant notre barque (la coque et les deux rames) sont détachés de l'objet source, puis donnés à l'objet destination. Aucune opération de copie n'est donc effectuée, puisque la coque et les rames ne sont pas recréés mais simplement déplacés : il s'agit des mêmes objets. L'objet source se retrouve alors vidé de sa consistance et ne doit plus être utilisé.
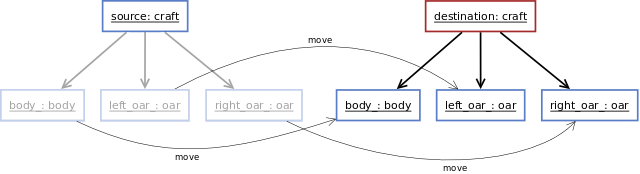
Cette définition du déplacement étant pour le moins abstraite, une mise en pratique sera certainement plus parlante. Le code ci-dessous (toujours écrit en C++98) redéfinit la classe craft. La première différence notable par rapport à la version précédente est le type d'allocation des champs de la classe : ceux-ci sont alloués sur le tas. La seconde modification se situe dans constructeur par copie. Ce dernier implémente cette fameuse opération de déplacement.
classcraft{public:craft():body_(newbody()),left_oar_(newoar()),right_oar_(newoar()){}//constructeur par "copie"craft(craft&o)://l'objet source doit être mutable, puisqu'il est modifiébody_(o.body_),//attribution des champsleft_oar_(o.left_oar_),//au nouvel objetright_oar_(o.right_oar_)//destination{o.body =0;//on dépossèdeo.left_oar_ =0;//l'objet sourceo.right_oar =0;//de ses champs}~craft(){//pas de problème de double libération//de ressource (double free),//puisque "delete 0;" n'a aucun effetdeleteright_oar_;deleteleft_oar_;deletebody_;}private:body*body_; oar*left_oar_; oar*right_oar_;};
La clé de la mise en oeuvre du déplacement est l'allocation sur le tas des champs de l'objet source. Le déplacement des champs se résume alors à quelques affectations de pointeurs. Le cout en ressources de ces quelques affectations étant tout à fait négligeable comparé à la lourdeur que peut induire une opération de copie, on peut sagement conclure sur la légitimité de cette alternative qu'est le déplacement.
Nous venons de le voir, le déplacement peut s'avérer incomparablement plus rapide que la copie. Il est toutefois nécessaire d'éclaircir un point : dans quels cas l'un doit être préféré à l'autre ?
Une fois l'opération de déplacement accomplie, l'objet source se retrouve privé de ses ressources. Il n'y a alors plus aucun intérêt à l'utiliser (il peut même être dangereux de le faire, à cause de la présence éventuelle de pointeurs nuls). Le déplacement n'a donc pas vocation à remplacer la copie quelle que soit la situation. En effet, lorsque nous produisons une copie, nous souhaitons la plupart du temps pouvoir continuer à utiliser l'objet original aussi bien que nous comptons faire usage du nouvel objet destination. Autrement dit, la duplication de l'ensemble des ressources peut s'avérer tout à fait souhaitée.
En revanche, il peut être très avantageux d'effectuer un déplacement lorsque l'objet source est un objet temporaire dont le seul destin aurait de toutes façons été la destruction, immédiatement après sa copie. Souvenez-vous en effet de l'incohérence que nous avions soulevée dans la section 2-1-1, « Premier exemple ».
Le déplacement permet donc de réutiliser les ressources d'un objet sur le point d'être détruit, le tout sans effectuer la moindre copie.
À ce point de l'article, vous êtes probablement en train de vous demander ce qu'il peut bien manquer à C++98 sur ce plan pour qu'on ait besoin d'y changer quoi que ce soit. Cela est bien légitime. Après tout, nous venons de faire la preuve qu'il est tout à fait possible d'implémenter le déplacement avec les outils que le standard de 1998 nous propose. Bien tenté. Hélas, vous faites erreur.
Écrivons tout d'abord une nouvelle version de notre classe craft, qui tente d'implémenter à la fois une construction par copie et une construction par déplacement :
classcraft{public:craft():body_(newbody()),left_oar_(newoar()),right_oar_(newoar()){}//constructeur par copiecraft(constcraft&o):body_(newbody(*o.body_)),left_oar_(newoar(*o.left_oar_)),right_oar_(newoar(*o.right_oar_)){std::cout<<"Copy construction\n";}//constructeur par déplacementcraft(craft&o):body_(o.body_),left_oar_(o.left_oar_),right_oar_(o.right_oar_){std::cout<<"Move construction\n"; o.body_ =0; o.left_oar_ =0; o.right_oar_ =0;}~craft(){deleteright_oar_;deleteleft_oar_;deletebody_;}private:body*body_; oar*left_oar_; oar*right_oar_;};
Cette tentative est vouée à l'échec pour deux raisons : l'une concerne la sécurité, l'autre démontre l'inefficacité pure et simple de cette solution.
Voici un exemple simple d'utilisation de la nouvelle version de craft. Nous en créons une instance, puis tentons de faire une copie de cette instance, comme nous le ferions pour n'importe quelle classe :
intmain(){craft c; craftcopy_of_c(c);//tentative de copiereturn0;}
Hélas, comme l'atteste la sortie produite par le programme, ce n'est pas le constructeur par copie qui est appelé, mais le constructeur par déplacement :
Move construction
Ce n'est pas vraiment une surprise. L'objet c n'étant pas constant, la surcharge de constructeur sélectionnée est celle effectuant le déplacement. C'est un problème, car la syntaxe employée est celle réservée à la copie ; nous croyons effectuer une copie, mais nous effectuons en fait un déplacement et rendons ainsi inutilisable l'objet c. Si nous avons le malheur de nous servir de cet objet pour effectuer une opération de lecture ou d'écriture sur l'un des ses champs, c'est l'erreur de segmentation assurée :
intmain(){craft c; craftcopy_of_c(c);//tentative de copieconstoar&leaf_oar = c.leaf_oar();//badaboumreturn0;}
Bien sûr, nous pourrions argumenter sur la discutable légitimité de passer une référence constance de c pour la construction de copy_of_c afin de provoquer l'appel au constructeur attendu. Mais de toutes façons, comme nous allons le voir immédiatement, le cas que nous venons d'étudier n'est même pas le plus rédhibitoire.
Souvenez-vous du problème soulevé dans la section 2-1, « Création de nombreuses copies inutiles ». Nous nous intéressons au déplacement car beaucoup de copies inutiles sont créées lors des transferts d'objets. Voyons comment s'en sort notre tentative de solution sur ce terrain là. Écrivons une fonction fabrique create_craft() et appelons la pour initialiser un objet de type craft :
craftcreate_craft(){returncraft();}intmain(){craft c =create_craft();return0;}
Cette fois-ci, et c'est plus surprenant, ce n'est pas le constructeur par déplacement qui est appelé, mais le constructeur par copie !
Copy construction Copy construction
Il est même appelé deux fois, pour les mêmes raisons que le cas de la section 2-1-2, « Deuxième exemple ».
Là encore, la raison est simple. Il est impossible de lier une référence non-constante à un objet temporaire :
constcraft&c =create_craft();//OKcraft&c =create_craft();//erreur de compilation
C'est donc tout naturellement notre constructeur par copie qui est appelé.
Toutes les ressources des objets temporaires sont donc copiées, ce qui est précisément ce que nous voulions éviter. Notre tentative d'écrire un constructeur par déplacement en C++98 est donc un échec.
La section précédente montre que, de toute évidence, il n'est pas possible de mettre correctement en place une construction par déplacement en C++98 (ou en tout cas pas de façon intuitive). Certains des objets censés être copiés subissent un déplacement, tandis que ceux que nous souhaitons déplacer sont copiés.
Quand effectuer une copie ? Quand effectuer un déplacement ? Les différents cas sont clairement identifiables, mais le standard de 1998 n'est pas capable de faire cette distinction. Il manque au standard la totale prise en compte de la notion de déplacement au sein même du langage.
L'ensemble des modifications et des nouveautés apportées au C++ pour rendre enfin possible une intégration efficace du déplacement se résume en une expression : la sémantique de déplacement (également appelée sémantique de mouvement, ou encore move semantics).
Les rvalue references sont la clé de cette sémantique. Ce sont elles qui vont nous permettre d'écrire des fonctions implémentant le déplacement ou faisant usage de celui-ci. Les notions de construction par déplacement et d'assignation par déplacement feront alors pleinement partie du langage.
Avant d'aborder le sujet de ces fameuses rvalue references, il convient de rappeler ce que sont les lvalues et les rvalues.
En C++, toute expression donnée est soit une lvalue, soit une rvalue. Il est en effet important de noter que les lvalue et rvalue désignent des expressions et non des valeurs.
Les termes lvalue (contraction de left hand side value, valeur située à gauche) et rvalue (contraction de right hand side value, valeur située à droite) prenaient pleinement leur sens lors de la définition initiale des concepts auxquels ils sont associés. Par exemple, en langage C, une lvalue est simplement une expression qu'il est possible de situer à gauche d'un opérateur d'assignation. Les rvalues, quant à elles, désignent toutes les expressions n'étant pas des lvalues, à savoir toutes les expressions ne pouvant pas être situées à gauche d'un opérateur d'assignation (donc uniquement à droite).
Bien que les termes d'origine aient été conservés, cette définition n'est pas tout à fait exacte en C++. Ici, une lvalue est une expression associée à une entité dont la durée de vie dépasse le cadre de l'instruction ou de la déclaration où se situe cette expression. Par exemple, dans le code suivant :
inttab[] ={0,2,4,6,8};inti;//Dans l'instruction suivante, l'expression "tab[2]" est associée à la troisième case du tableau tab.i = tab[2];//Dans la suite du code, la troisième case de tab existe toujours !tab[2] =12;//etc.
l'expression tab[2] est une lvalue. De façon plus générale, les expressions telles que obj, *ptr ou ptr[index] sont également des lvalues.
A contrario, les entités associées aux rvalues sont détruites dès l'instruction exécutée. Il s'agit d'entités temporaires :
doubled;//Dans l'instruction suivante, l'expression "21 * 2" est associée à un entier temporaire valant 42.d =21*2;//Dans la suite du code, l'entier temporaire n'existe plus...d =24.5;//... même si une copie a été placée (et approximée) dans la variable d//etc.
L'expression 21 * 2 du code ci-dessus est une rvalue.
Parmi les rvalues on compte :
return).
[à compléter pour les valeurs de retour]
Outre ces définitions théoriques, il existe un moyen pratique de différencier ces deux types d'expressions : les entités associées aux lvalues sont les seules dont nous pouvons récupérer l'adresse. Autrement dit, si nous pouvons faire précéder une expression de l'opérateur & unaire, alors il s'agit d'une lvalue :
inti;int*ptr_i =&i;int&ref_i = i;inttab[5];//lvalues&i;//OK&*ptr_i;//OK&ref_i;//OK&++i;//OK&tab[3];//OK//rvalues//&42; //erreur//&(40 + 2); //erreur//&true; //erreur//&f(); //erreur//&'A'; //erreur//&i++; //erreur
| L'exception des chaines de caractères littérales |
|---|---|
Pour des raisons de performances, les chaines de caractères littérales sont allouées statiquement en mémoire ; c'est-à-dire qu'elles sont chargées en mémoire avant même le début du programme et ne sont déchargées que lorsque ce dernier se termine. En pratique, ces chaines ne sont donc pas des entités temporaires allouées dynamiquement sur la pile comme le sont les autres types d'entités liées aux rvalues. Il est d'ailleurs tout à fait possible de récupérer l'adresse mémoire d'une chaine de caractères littérale : l'expression Toutefois, malgré cette particularité d'ordre purement pratique (compte tenu de leurs tailles potentiellement élevées, allouer dynamiquement ces chaines aurait été peu judicieux), les chaines de caractères littérales n'en sont pas moins considérées comme des rvalues. |
| Le cas des opérations d'incrémentation |
|---|---|
Fait bien plus anecdotique encore, les opérations de préincrémentation (
En effet, la valeur de l'expression
La valeur de l'expression
C'est en outre parce qu'on évite la création d'une variable temporaire que la notation de préincrémentation est préférée. |
Le lecteur attentif aura constaté que les problèmes auxquels nous sommes confrontés depuis le début de ce cours, en particulier dans la partie mettant en avant les limites du standard de 1998, mettent en scène des rvalues en tant qu'actrices principales. Ce sont en effet des rvalues, et plus précisément des appels de fonctions (constructeurs compris) et des expressions arithmétiques, qui sont au centre de ces cas. Nous reviendrons sur ce point quelques sections plus loin.
Le langage C++0x introduit les rvalue references, qui cohabitent avec les références classiques de C++98 (que nous nommerons désormais lvalue references). Les rvalue references se notent avec deux esperluettes au lieu d'une seule :
int&lref;//ceci est une lvalue referenceint&&rref;//ceci est une rvalue reference
Les rvalue references ont à première vue la même fonction que les lvalue references, à savoir faire référence à une variable ou un objet existant. Leurs caractéristiques présentent toutefois deux nuances d'une importance capitale :
Elles peuvent être liées à des rvalues sans nécessairement avoir à être constantes (nous avions effectivement constaté dans la section 4-2, « Impossibilité d'implémenter une construction par déplacement fonctionnelle » qu'une lvalue reference devait être constante pour pouvoir être liée à une rvalue) :
inti;constint&lref =40+2;//la rvalue liée à lref peut être lue, mais pas modifiéei = lref;//OK//lref += 4; //erreurint&&rref =40+2;//la rvalue liée à rref peut être lue ET modifiéei = rref;//OKrref +=4;//OK
Dans le cas où il existe deux surcharges d'une fonction, où l'une prend en paramètre une lvalue reference, et l'autre une rvalue reference du même type :
voidf(constint&){std::cout<<"I'm an lvalue.\n";}voidf(int&&){std::cout<<"I'm an rvalue.\n";}intmain(){inti =0; f(i); f(42);}
I'm an lvalue. I'm an rvalue.
La solution se trouve bel et bien dans ce nouveau type de références. Ces deux caractéristiques comblent en effet à elles seules les manques de C++98 qui nous empêchaient d'implémenter correctement la construction et l'assignation par déplacement. Ces deux opérations font l'objet de la section suivante.
Les rvalue references apportent tout ce dont nous avons besoin pour implémenter une construction (et une assignation) par déplacement à la fois sécurisée et fonctionnelle : le constructeur par copie est appelé lors du passage d'une lvalue, et le constructeur par déplacement l'est pour une rvalue. Ce comportement est celui que nous recherchions depuis le début, avant même d'avoir défini ce qu'étaient les lvalues et rvalues. En effet, si nous revenons à la section concernant la propension du C++98 à faire usage de la copie dans des cas peu légitimes, nous constatons que les valeurs mises en scène sont toutes sans exception des rvalues :
Merci à
Les sources présentées sur cette page sont libres de droits et vous pouvez les utiliser à votre convenance. Par contre, la page de présentation constitue une œuvre intellectuelle protégée par les droits d'auteur. Copyright © 2008 Florian Goujeon. Aucune reproduction, même partielle, ne peut être faite de ce site ni de l'ensemble de son contenu : textes, documents, images, etc. sans l'autorisation expresse de l'auteur. Sinon vous encourez selon la loi jusqu'à trois ans de prison et jusqu'à 300 000 € de dommages et intérêts.
